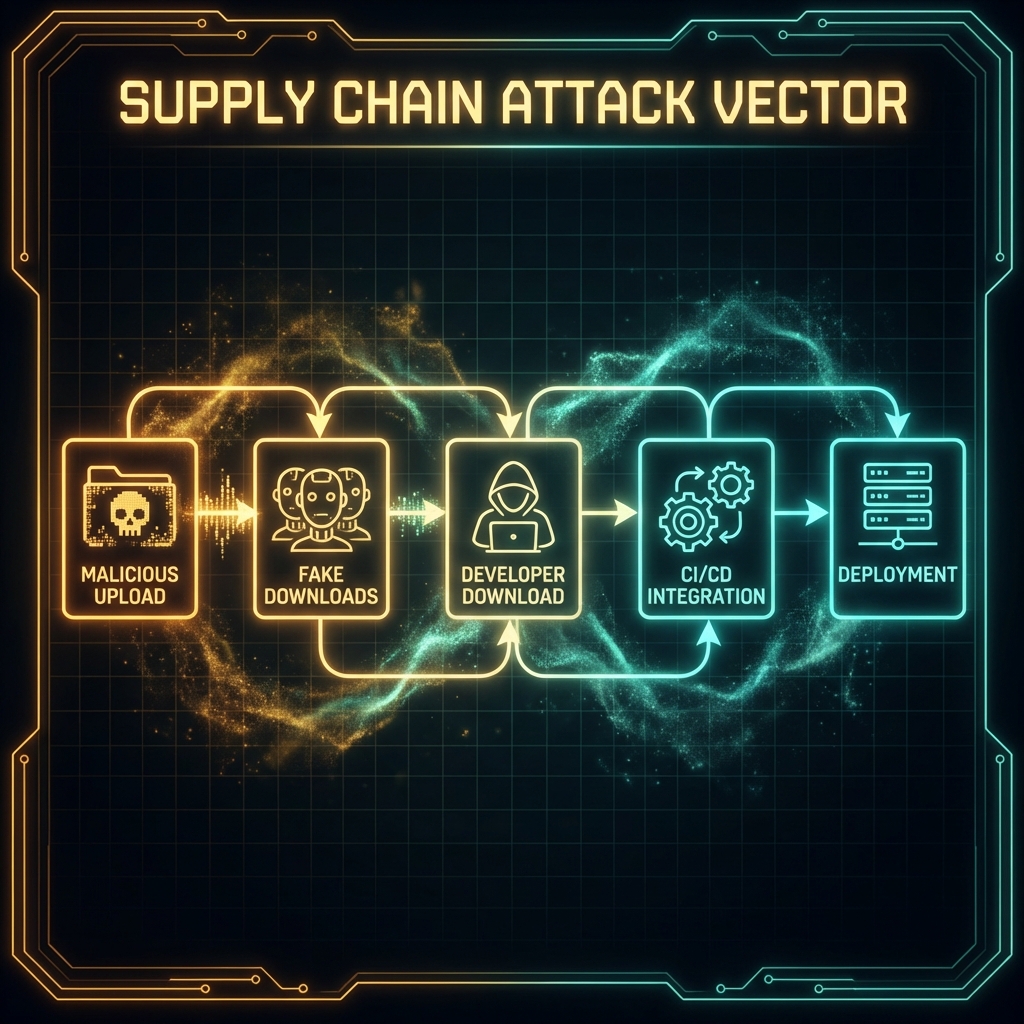
# 26. Supply Chain Attacks on AI