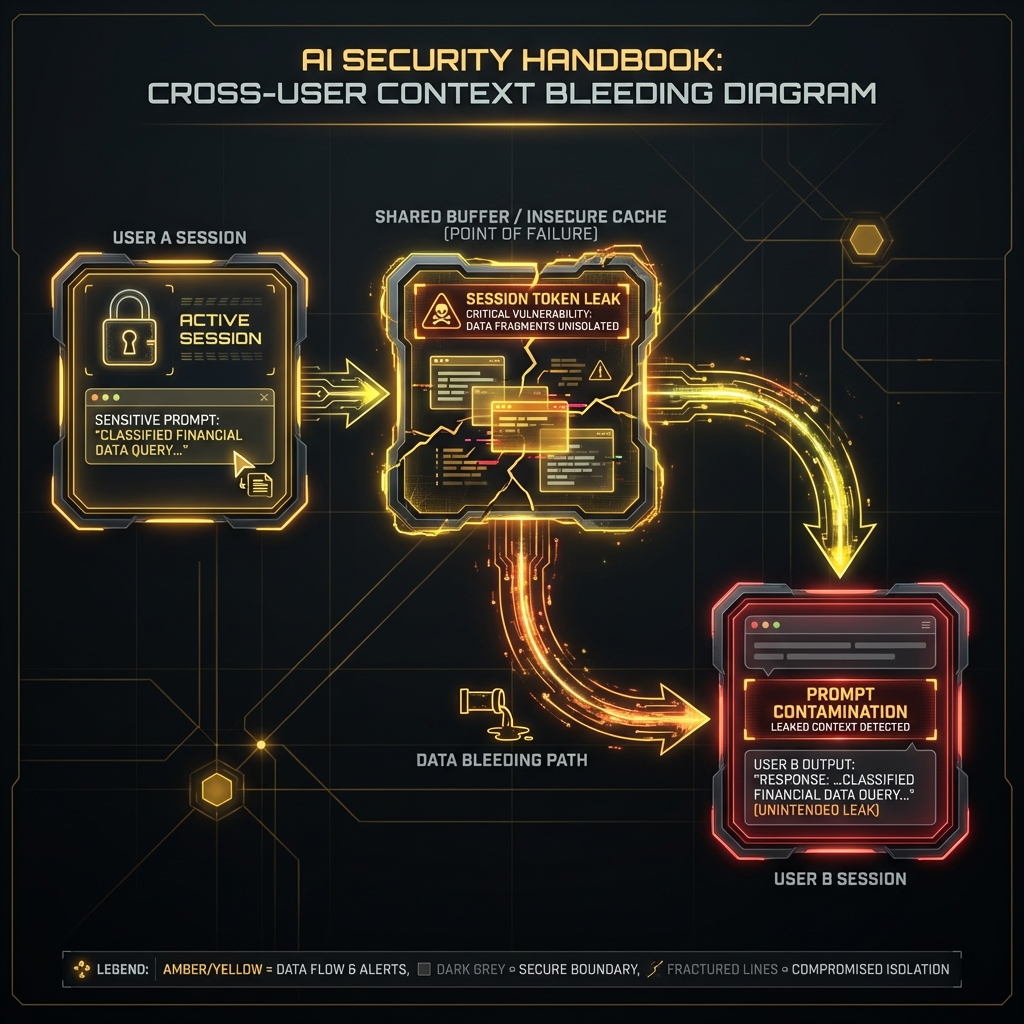
# 15. Data Leakage and Extraction